improvement in quality scores over 6 months
Real-Time Call Center Performance Intelligence
Meridian Financial Services
Transforming quality assurance from 2% manual call sampling to 100% AI-powered coverage with multi-model analysis, real-time compliance monitoring, and live coaching intervention.
Quick Facts
Meridian Financial Services
Meridian Financial Services is a mid-sized financial services firm operating a 1,200-seat contact center across three locations in Atlanta, Charlotte, and Nashville. Handling 4.2 million customer interactions annually, their agents manage customer service, collections, account management, and retention programs across a highly regulated environment governed by CFPB and FDCPA requirements with 24/7 operations.
The Organization
- 1,200 agents across 3 facilities (Atlanta, Charlotte, Nashville)
- 4.2 million annual customer interactions
- Services: customer service, collections, account management, retention
- Highly regulated environment (CFPB, FDCPA compliance)
- 24/7 operations with multi-shift coverage
Business Complexity
- Regulatory oversight: CFPB, FDCPA, state banking regulations
- $5K–$50K fines per compliance violation
- 98% of calls went unreviewed by quality assurance
- $1.17M annual QA costs with an 18-person review team
Quality Assurance Challenge
Meridian's 18-person QA team could only manually review approximately 2% of calls, leaving the vast majority of customer interactions unexamined. This created significant blind spots in quality oversight, compliance monitoring, and agent development.
- 98% of calls went completely unreviewed, creating massive quality blind spots
- Weeks-long delays between calls and feedback made coaching ineffective
- Inconsistent evaluation standards across 18 different QA analysts
- Critical compliance violations hidden in the unreviewed 98%
- Limited visibility into quality trends, patterns, and systemic issues
- High costs with minimal coverage — $1.17M annually for 2% review rate
Meridian represents a universal enterprise contact center challenge: achieving 100% quality visibility, enabling real-time intervention during live calls, and doing so cost-effectively. Their situation demanded a solution that could simultaneously monitor every interaction, flag compliance risks in real time, and provide actionable coaching — something no manual process or traditional tool could deliver.
Quality Assurance Drowning in Data, Starved for Insights
With 4.2 million customer interactions annually and only 2% manually reviewed, Meridian's QA managers knew they were missing critical problems. Compliance violations went undetected for weeks, struggling agents received feedback too late to course-correct, and top performers went unrecognized. The data was there — buried in millions of unreviewed calls — but the team had no way to surface it at scale.
The Manual QA Bottleneck
2% Call Coverage = Massive Blind Spots
With 18 analysts reviewing just 80,000 of 4.2 million annual calls, Meridian could only evaluate approximately 24 calls per agent per month. Random sampling missed critical issues entirely — high performers were under-recognized while struggling agents were over-coached based on small, unrepresentative samples.
Weeks-Long Feedback Delays
QA reviews typically occurred 2–4 weeks after the actual call. By then, agents could not remember the specific interaction, making coaching feel punitive rather than constructive. Supervisors had no ability to correct issues in real time, and problematic patterns continued unchecked for weeks before detection.
Inconsistent Evaluation Standards
With 18 different QA analysts, subjective dimensions like "empathy" were scored differently depending on who reviewed the call. Agent scores depended more on which reviewer they drew than on their actual performance. Calibration sessions helped but could not fully resolve limited inter-rater reliability, making it hard to defend evaluation decisions.
Invisible Compliance Risk
Operating under multiple regulatory frameworks including CFPB, FDCPA, and state banking regulations, Meridian faced significant compliance exposure. With only 2% of calls reviewed, violations in the remaining 98% went undetected — creating a ticking regulatory time bomb.
The Stakes
- FDCPA violations: $1,000 per incident in statutory damages
- CFPB enforcement actions: $5,000–$50,000+ per violation
- Reputational damage from regulatory findings and consent orders
- Investigation costs, legal fees, and remediation expenses
Common Undetected Issues
- Skipped required disclosures during collections calls
- Script deviations on regulated product offers and credit terms
- Improper escalation handling on complaint calls
- Omitted recording consent notifications in required states
What They Had Already Tried
Increase QA Staffing
Adding 12 more analysts would have increased coverage to just 5% at a cost of $780K annually. Leadership rejected the proposal as insufficient improvement for the investment required.
Off-Shore QA Review
A Philippines-based pilot team was brought in to increase review volume at lower cost. However, cultural context was consistently lost in evaluations, leading to inaccurate scores. The program was terminated after 3 months.
Speech Analytics Software
A $180K/year keyword-based speech analytics platform was deployed but produced high false positive rates due to its inability to understand context. It supplemented manual review but could not replace it or provide real-time intervention.
Meridian faced three goals that seemed mutually exclusive with traditional approaches: comprehensive coverage (reviewing every call, not just a sample), real-time feedback (intervening during calls, not weeks later), and cost efficiency (spending less, not more, on quality assurance). Every solution they tried forced them to choose one or two — none could deliver all three.
From Sampling to 100% Coverage
Discovery Phase (6 weeks)
QA Process Immersion
We shadowed 8 QA analysts over 40+ hours, observing how they evaluated calls in real time. We analyzed scorecards across 12 quality dimensions, reviewed 500+ historical evaluations for patterns and inconsistencies, and observed live monitoring sessions to understand the gap between what analysts could do and what the operation actually needed.
Expert Analysts Looked Beyond Checklists
The best QA analysts did far more than check boxes. They identified context that changed how a response should be evaluated, recognized when appropriate deviations from script actually improved outcomes, connected individual call patterns to broader agent development needs, provided actionable feedback tied to specific moments, and detected systemic patterns across multiple interactions.
The AI system needed to model expert judgment, not just replicate checklists. Surface-level automation would miss the nuance that made great QA valuable.
Different Dimensions Need Different AI Models
Testing revealed that no single AI model excelled across all quality dimensions. Objective, rules-based dimensions like compliance adherence, data accuracy, process following, and script adherence were best handled by Claude, which excelled at structured reasoning. Subjective, nuance-based dimensions like empathy, customer satisfaction, emotional intelligence, and rapport building were better evaluated by GPT-4, which showed stronger performance on sentiment and emotional context.
Multi-model orchestration consistently outperforms any single-model approach. Playing to each model's strengths produced evaluations that matched expert human reviewers.
Real-Time Feedback Was the Game-Changer
Supervisors could only monitor 3–4 agents simultaneously using traditional tools, leaving hundreds of active calls unobserved. The discovery phase revealed that real-time scoring during live calls, automated alerts for compliance risks, immediate coaching triggers for struggling agents, and the ability to prevent bad patterns before they compound would deliver exponentially more value than even perfect retrospective analysis.
Real-time analysis provides exponentially more value than retrospective review. Preventing a compliance violation is worth far more than detecting it weeks later.
Technical Architecture Decisions
Multi-Model Orchestration
Claude 3.5 Sonnet handles compliance checks, regulatory adherence, script following, and rules-based evaluation. GPT-4 handles empathy scoring, sentiment analysis, emotional intelligence assessment, and rapport evaluation. Each model is deployed where its strengths align with the evaluation dimension.
Rationale: Playing to each model's strengths produces evaluations that consistently match or exceed expert human reviewers across all 12 quality dimensions.
Real-Time Streaming Pipeline
Five9 streams live call audio through Apache Kafka, feeding automated transcription with incremental analysis. The pipeline generates compliance alerts in real time, triggers coaching interventions during active calls, and produces comprehensive post-call quality scores within seconds of call completion.
Rationale: Real-time intervention during a live call is worth exponentially more than perfect retrospective analysis delivered weeks later.
Human-in-the-Loop Validation
The AI provides scores and flags potential issues, but QA analysts review all flagged compliance violations before action is taken. Analysts calibrate models through feedback loops, handle edge cases requiring human judgment, and validate that AI evaluations align with organizational standards.
Rationale: Trust through transparency. Agents and supervisors trust the system because they know a human validates critical decisions, and the AI improves continuously from that feedback.
Real-Time Call Center Performance Intelligence
100% Call Coverage with Multi-Model AI Analysis and Live Coaching Intervention
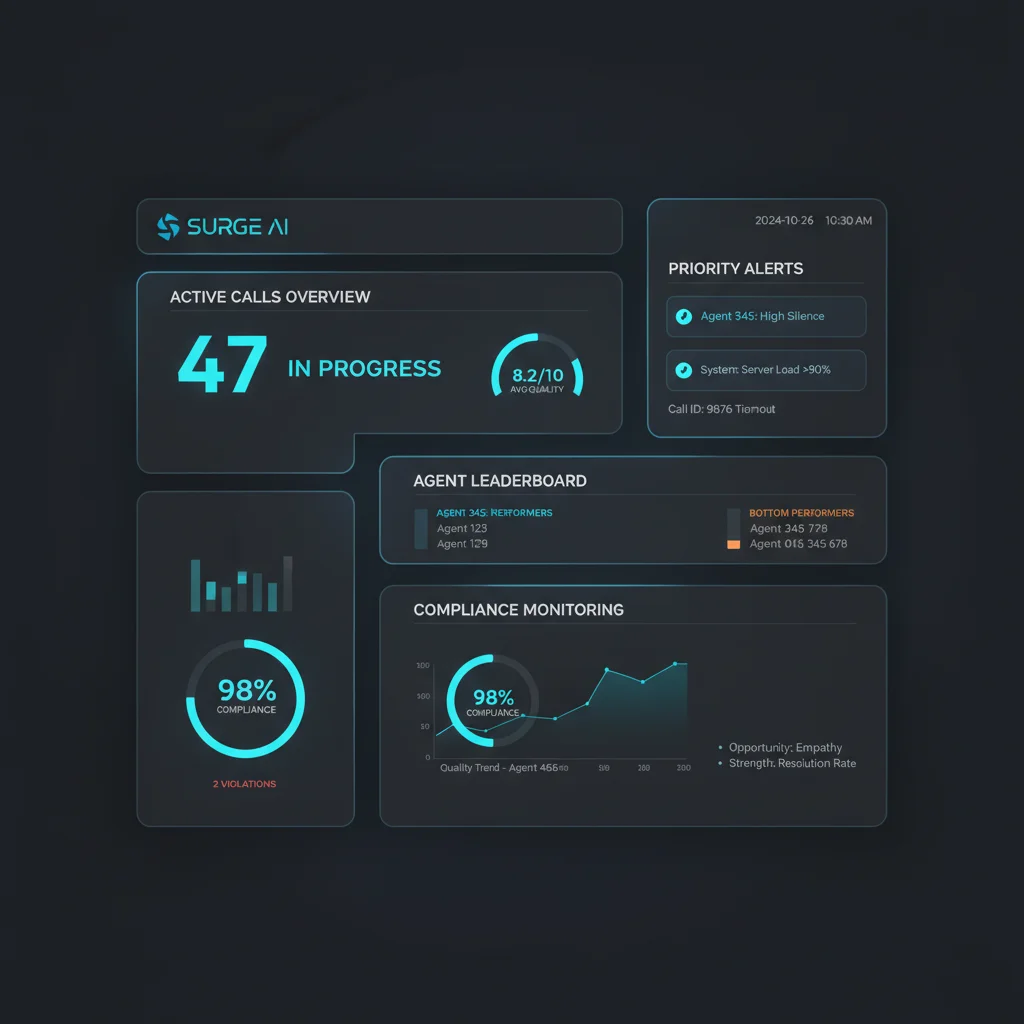
The platform analyzes every customer interaction in real time using a multi-model AI architecture, providing supervisors with live dashboards, automated compliance alerts, and coaching intervention tools — while giving agents daily performance feedback and self-improvement resources.
Multi-Dimensional Quality Scoring
Compliance (Claude): regulatory adherence, data accuracy, process following, script compliance. Experience (GPT-4): empathy, active listening, clarity, professionalism. Outcome (ensemble): issue resolution, first-call resolution prediction, CSAT prediction, efficiency.
Real-Time Compliance Monitoring
Monitors across FDCPA, CFPB, credit offer regulations, and state-specific requirements with 47 distinct risk categories. Severity levels trigger appropriate responses: critical issues generate immediate supervisor alerts, high-severity items require same-day review, medium issues are flagged for weekly analysis, and low-risk patterns feed monthly trend reports.
Sentiment Analysis & CSAT Prediction
Goes beyond simple positive/negative classification to understand multi-turn emotional context, detect implied emotions that are not explicitly stated, evaluate agent response effectiveness in de-escalation, and predict customer satisfaction with 89% correlation to actual post-call CSAT survey results.
Supervisor Dashboard
Live view of all active calls with real-time quality scoring, priority-ranked compliance alerts, agent performance leaderboard, and AI-generated coaching insights. Intervention capabilities include silent monitoring, whisper coaching for in-ear guidance, call takeover for critical situations, and real-time performance trend visualization.
Agent Dashboard
Each agent receives a daily scorecard summarizing their performance across all 12 quality dimensions, with comparison to team and peer benchmarks. Includes skill-by-skill tracking over time, self-review access to AI-scored call transcripts, and personalized coaching recommendations based on identified improvement areas.
Executive Dashboard
Provides leadership with quality trends across the entire operation, compliance risk exposure and mitigation tracking, quantified cost savings and ROI metrics, agent development pipeline visibility, and predictive analytics for staffing, training needs, and emerging quality issues before they become systemic problems.
Transforming Quality Assurance from Cost Center to Competitive Advantage
Quality Score Improvement
Average quality scores improved from 5.8 to 8.2 out of 10 across the organization. Compliance dimension scores increased 56%, customer experience scores improved 39%, and outcome-based scores rose 27%. The business impact was immediate: customer satisfaction (CSAT) increased 3.2 points, customer retention improved 4.7%, and $2.3M in customer lifetime value was retained that would otherwise have been lost to churn.
Call Coverage
Coverage expanded from 80,000 manually reviewed calls to all 4.2 million annual interactions — a 52.5x increase. Full coverage revealed that the estimated 847 annual compliance violations (based on sampling) was dramatically overstated: the actual number was 93 (an 89% reduction through real-time prevention). Analysis also showed that 8% of agents caused 67% of all violations, and weekend shift quality issues became visible for the first time.
Annual Cost Savings
QA staffing reduction from 18 to 6 analysts saved $780K annually (remaining staff elevated to strategic roles). Compliance violation avoidance saved $650K in potential fines and remediation. First-call resolution improvements saved $280K in repeat contact costs. Training efficiency gains contributed $90K in savings. After subtracting the $240K annual platform cost, net savings totaled $1.56M — a 650% return on investment.
Compliance Violation Reduction
Total violations dropped from an estimated 847 annually to just 93 confirmed incidents. Critical violations (immediate regulatory risk) fell from 140 to 3 — a 98% reduction. High-severity violations dropped from 320 to 18 (94% reduction). Medium-severity issues declined from 387 to 72 (81% reduction). The reduction in compliance exposure avoided an estimated $650K+ in potential fines, legal costs, and remediation expenses.
First-Call Resolution
68% to 83%
Customer Satisfaction
Quality directly correlated with CSAT
Agent Satisfaction
92% say feedback more helpful
Agent Turnover
Higher quality = higher retention
QA Team Role
From reviewers to strategic analysts
Growth Ready
Expand without proportional QA staff
Similar Challenges, Proven Results
Have a Similar Challenge?
Tell us about your project — we can help